I can’t believe it’s already been a year and a half since my last post… I’m sorry for the lack of content here. Things have been so busy at EMC as well as at home and so much of what I’ve been working on is customer proprietary that I’ve had trouble thinking of ways to write about it. In the meantime I’ve taken on a new role at EMC in the last month which will likely change what I’m thinking about as well as how I look at the storage industry and customer challenges.
In the past couple of years I’ve been involved in projects ranging from data lifecycle and business process optimization, storage array performance analysis, and scale out image and video repositories, to Enterprise deployments of OpenStack on EMC storage, Hadoop storage rationalization, and tools rationalization for capacity planning. It is these last three items that have, in part, driven me into taking on a new role.
For the first three and half years I’ve spent at EMC I’ve been an Enterprise Account Systems Engineer in the Pacific Northwest. Technically, I was first hired into the TME (Telco/Media/Entertainment) division focused on a small set (12 at first) of accounts near Seattle. After about a year of that, the TME division was merged into the Enterprise West division covering pretty much all large accounts in the area, but the specific customers I focused on stayed the same. For the past year or so I’ve spent pretty much 80% of my time working with a very large and old (compared to other original DotCom’s) online travel company. The rest of my time was spent with a handful of media companies. I’ve learned A TON from my coworkers at EMC as well as my customers. It’s amazing how much talent is lurking in the hallways of anonymous black glass buildings around Seattle, and EMC stands out as having the highest percentage of type-A geniuses (does that exist) of any place I’ve worked.
One of the projects I’ve been working on for a customer of mine is related to capacity planning. As you may know, EMC has several software products (some old, some new, some mired in history) dedicated to the task of reporting on a customer’s storage environment. These software products all now fall under the management of a dedicated division within EMC called ASD (Advanced Software Division). Over the past 13 years, EMC has acquired and integrated dozens of software companies and for a long time these software products were all point solutions that, when viewed as a set, covered pretty much every infrastructure management need imaginable. But they were separate products. In the past couple years alone massive progress has been made towards integrating them into a cohesive package that is much better aligned and easier to consume and use.
In just the past 12 months, one acquisition specifically, has greatly contributed to EMC’s recent, and I’ll say future, success in the management tools sector, and that is Watch4Net. More accurately the product was APG (Advanced Performance Grapher) from a company called Watch4Net, but now it is the flagship component of EMC’s Storage Resource Management (SRM) Suite.
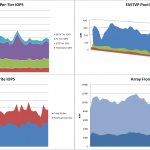
I’ve been spending a lot of time with SRM Suite lately at several customer sites and I’m really quite impressed. SRM Suite is NOT ECC (for those of you who know and love AND hate ECC), and it’s not ProSphere, or even what ProSphere promised; it’s better, it’s easier to deploy, it’s easier to navigate, it’s MUCH faster to navigate, it’s easier to customize (even without Professional Services), it’s massively extensible, and it works today! The Watch4Net software component is really a framework for collection, data storage, and presentation of data, and it includes dozens of Solution Packs (combinations of collector plug-ins and canned reports for specific products). And more Solution Packs are coming out all the time, and you can even make your own if you want to.
What I really like about SRM Suite is the UI that came from Watch4Net. It’s browser based (yes it supports IE, Chrome, Firefox, Mac, PC, etc) and you can easily create your own custom views from the canned reports. You can even combine individual components (ie: graphs or tables) from within different canned reports into a single custom view. And any view you can create, you can schedule as an emailed, FTP’d, or stored report with 2 clicks. Have an extremely complex report that takes a while to generate? Schedule it to be pre-generated at specific times during the day for use within the GUI, again with 2 clicks.
As slick as the GUI is, the magic of SRM Suite comes from the collectors and reports that are included for the various parts of your infrastructure. There are SolutionPacks for EMC and non-EMC storage arrays, multiple vendor FibreChannel switches, Cisco, HP, IBM servers, IP network switches and routers, VMware, Hyper-V, Oracle, SQL, MySQL, Frame-Relay, MPLS, Cisco WiFi networks, and many more. This single tool provides drill down metrics on individual ports of a SAN switch for a Storage Engineer, Capacity forecasting for management, as well as rollup health dashboards for your company’s executives all within the same tool. And those same Exec’s can get their reports on their iPhones and iPads with the Watch4Net APG iOS app anywhere they happen to be.
 (From vTexan’s post about SRM)
(From vTexan’s post about SRM)
It’s hard to paint the picture in words or even a few screenshots, so you should ask your local EMC SE for a demo!
The second Big Deal coming from EMC’s ASD division is EMC ViPR. ViPR is EMC’s Software Defined Storage solution. ViPR abstracts and virtualizes your SAN, NAS, Object, and Commodity storage into Virtual Pools and automates the provisioning process from LUN/FileSystem creation to masking, zoning, and host attach, all with Service Level definitions, Business Unit and Project role-based access, and built in chargeback/showback reporting. A full web portal for self-service is included as well as a CLI but the real power is the fully capable REST API which allows your existing automation tools to issue requests to ViPR, to handle end-to-end provisioning of your entire environment. Best of all ViPR has open APIs and supports heterogenous (ie: EMC and non-EMC storage) allowing you to extend the single ViPR REST API to all of your disparate storage solutions.
Looking at the future of the storage industry, as well as EMC as a company, I see ViPR, in combination with SRM Suite, as the place to be for the next few years at least. And so that’s what I’m doing. Right now I’m in the process of transitioning from my Account SE role into being one of just a handful of ASD Software Specialist SE’s (sometimes also referred to as SDSpecialists). In my new roll I’ll be the local Specialist for SRM Suite, ViPR, Service Assurance Suite (aka EMC Smarts), and several other EMC products you probably never thought of as software, or probably never heard of. There are many enhancements to all of the products on the near term roadmap which will further solidify the ASD software portfolio as market leading but I can’t talk to much about that here.. So ask your local EMC SE to set up a roadmap discussion at the same time as the demo you already asked for.
I do plan to get to writing more often again, and I believe that my new role in the ASD organization will provide good content for that.
More soon!