

Through a series of discussions with a friend who was evaluating solar for his home, doing some calculations, and discussing with the local contractor, I bit the bullet last month and got a 9800 watt solar array installed on our house here in the Pacific Northwest. While pricey up front there are a number of incentives available from the Federal government as well as Washington State that effectively pay for the entire system. I’ll write-up the cost analysis later but for now let’s take a look at the performance of the system..
 The roof of our house has 4 sides with trees lining the entire East side of the property, causing some shading in the morning. The majority of the North and South sides are clear and the West side is completely open. Due to this, the 35 x 280 watt panels cover pretty much the entire West roof and a large portion of the South roof. Our system uses the more expensive micro-inverters in order to handle shading of a single panel without affecting the rest of the system. Aside from more efficiency in shading situations, the micro-inverters have about double the life of the less-expensive in-line inverters. Our system is also grid-tied and we do not have any batteries involved. Since the micro-inverters push 240VAC power down from the roof, the interconnection with our panel is very simple. In order to take advantage of Washington State’s solar incentive the local power utility (Puget Sound Energy) installed a “Production Meter” that measures how many kWh’s the system generates irrespective of how it gets used. And in order to take advantage of the grid-tied solar system to reduce my power bill they installed a new digital “Net Meter” that tracks both how much power I consume from the grid and how much our system pushes TO the grid. The difference between those numbers determines the actual billed amount each month.
The roof of our house has 4 sides with trees lining the entire East side of the property, causing some shading in the morning. The majority of the North and South sides are clear and the West side is completely open. Due to this, the 35 x 280 watt panels cover pretty much the entire West roof and a large portion of the South roof. Our system uses the more expensive micro-inverters in order to handle shading of a single panel without affecting the rest of the system. Aside from more efficiency in shading situations, the micro-inverters have about double the life of the less-expensive in-line inverters. Our system is also grid-tied and we do not have any batteries involved. Since the micro-inverters push 240VAC power down from the roof, the interconnection with our panel is very simple. In order to take advantage of Washington State’s solar incentive the local power utility (Puget Sound Energy) installed a “Production Meter” that measures how many kWh’s the system generates irrespective of how it gets used. And in order to take advantage of the grid-tied solar system to reduce my power bill they installed a new digital “Net Meter” that tracks both how much power I consume from the grid and how much our system pushes TO the grid. The difference between those numbers determines the actual billed amount each month.
For example, if we push 1000 kWh into the grid during the month, and pull 900 kWh, then our bill that month will show a credit equal to 100 kWh. That credit can be used in a later month (ie: the winter months) when we might be consuming more than we generate each day.
At about 7pm PT today pulled statistics from the micro-inverters as well as the current readings on the ‘net’ and ‘production’ meters. The system came online during the morning of May 29th. The cumulative numbers for the past ~12 days are as follows..
- Production Meter
- 580 kWh‘s generated by the solar array
- Net Meter
- 378 kWh‘s pushed to the grid
- 205 kWh‘s consumed from the grid
Doing the math, this means we’ve consumed approximately 387 kWh in that time from all sources (grid + solar). The summer has pretty much started here so at least for this time of year we are clearly generating significantly more that we consume. The winter months will be different of course. This also translates to a 173 kWh credit on our electric bill so far.
Let’s take a look at how the system performs on different days and at different times of day..
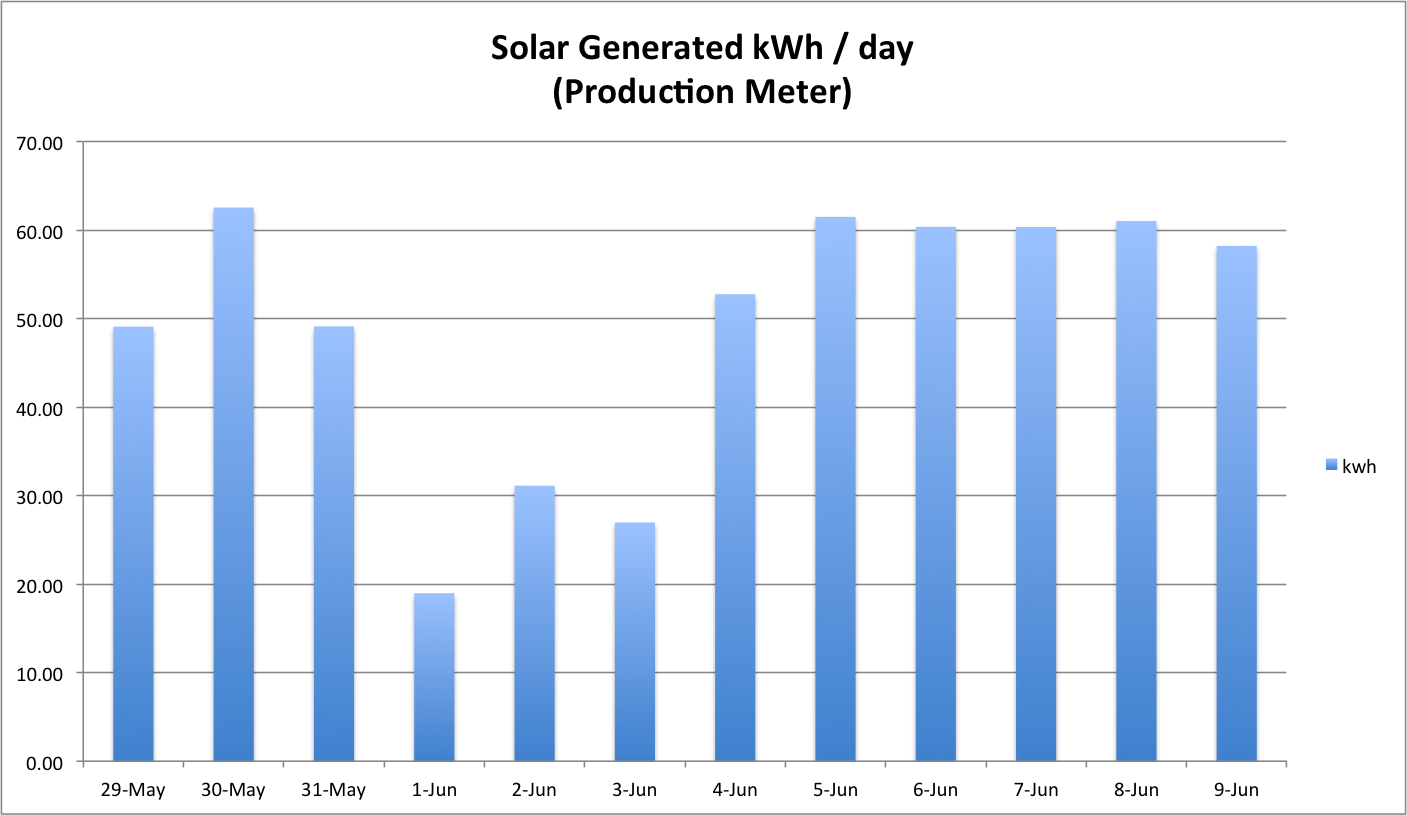
First, here is a look at how many kWh’s we are generating per-day. You will see that there are some stormy, rainy, cloudy, dark days mixed in with the other more sunny days..
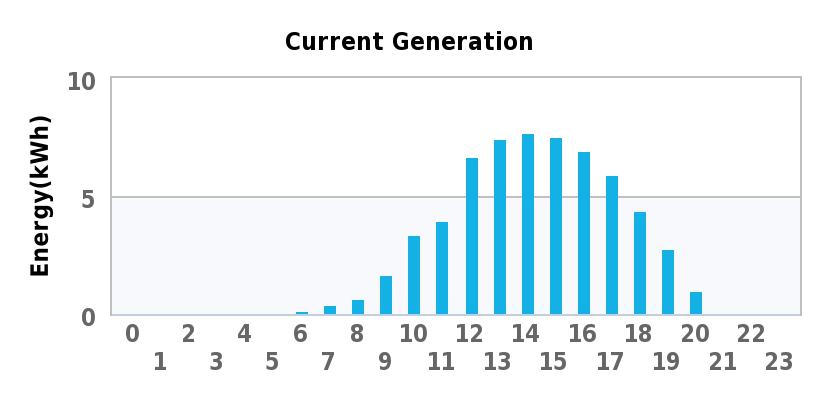
Now here are two charts, the first showing the amount of power being generated in watts through a 24 hour period on a nice sunny day and the second showing the number of kWh’s generated in each particular hour.
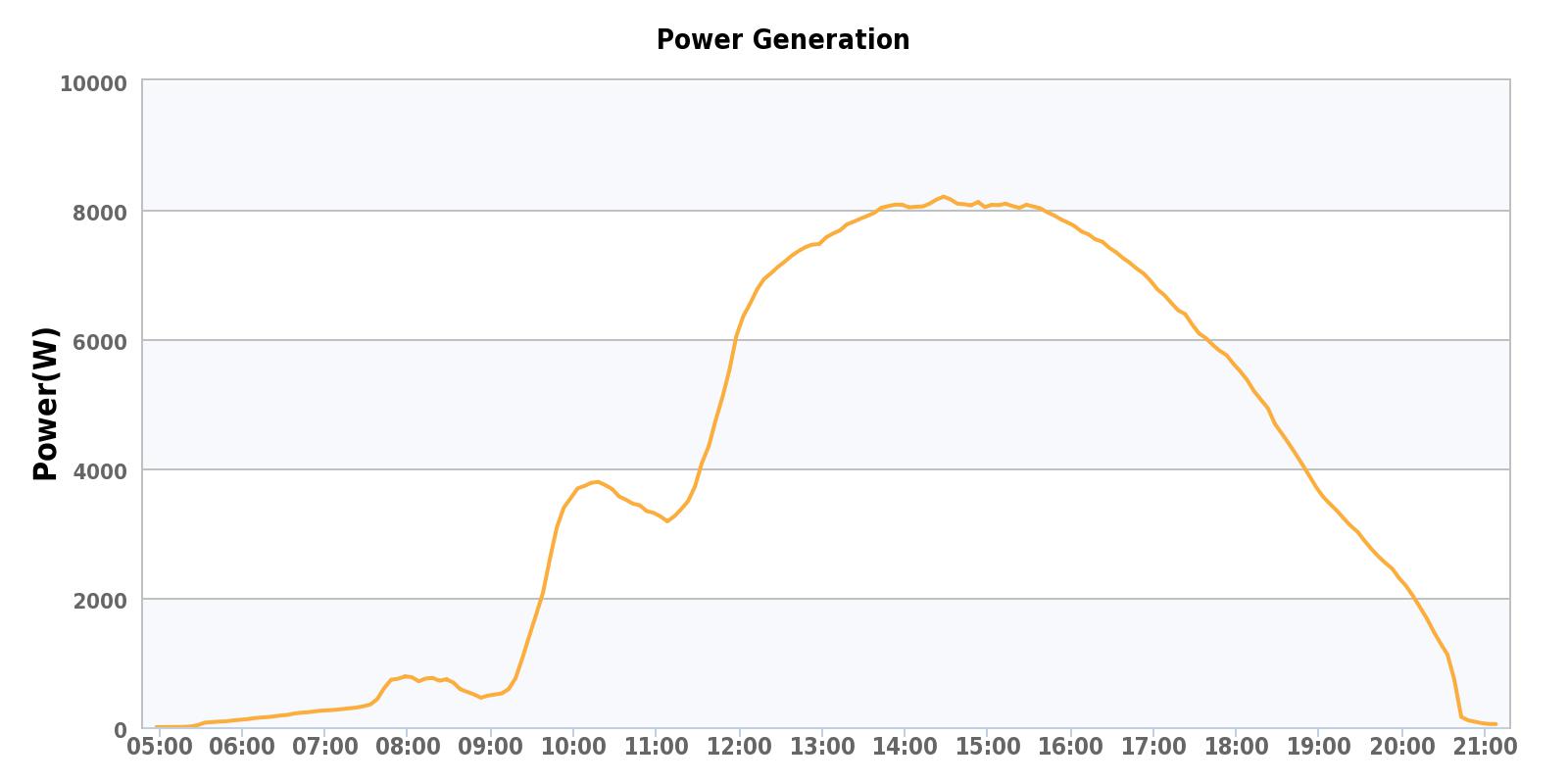
You may notice the dips around 9am and 11am. These are caused by the south side panels being partially shaded at those times as the sun moves across the sky.
 Here are the same two charts for the darkest, cloudiest, rainiest day we had a quite a while.
Here are the same two charts for the darkest, cloudiest, rainiest day we had a quite a while.
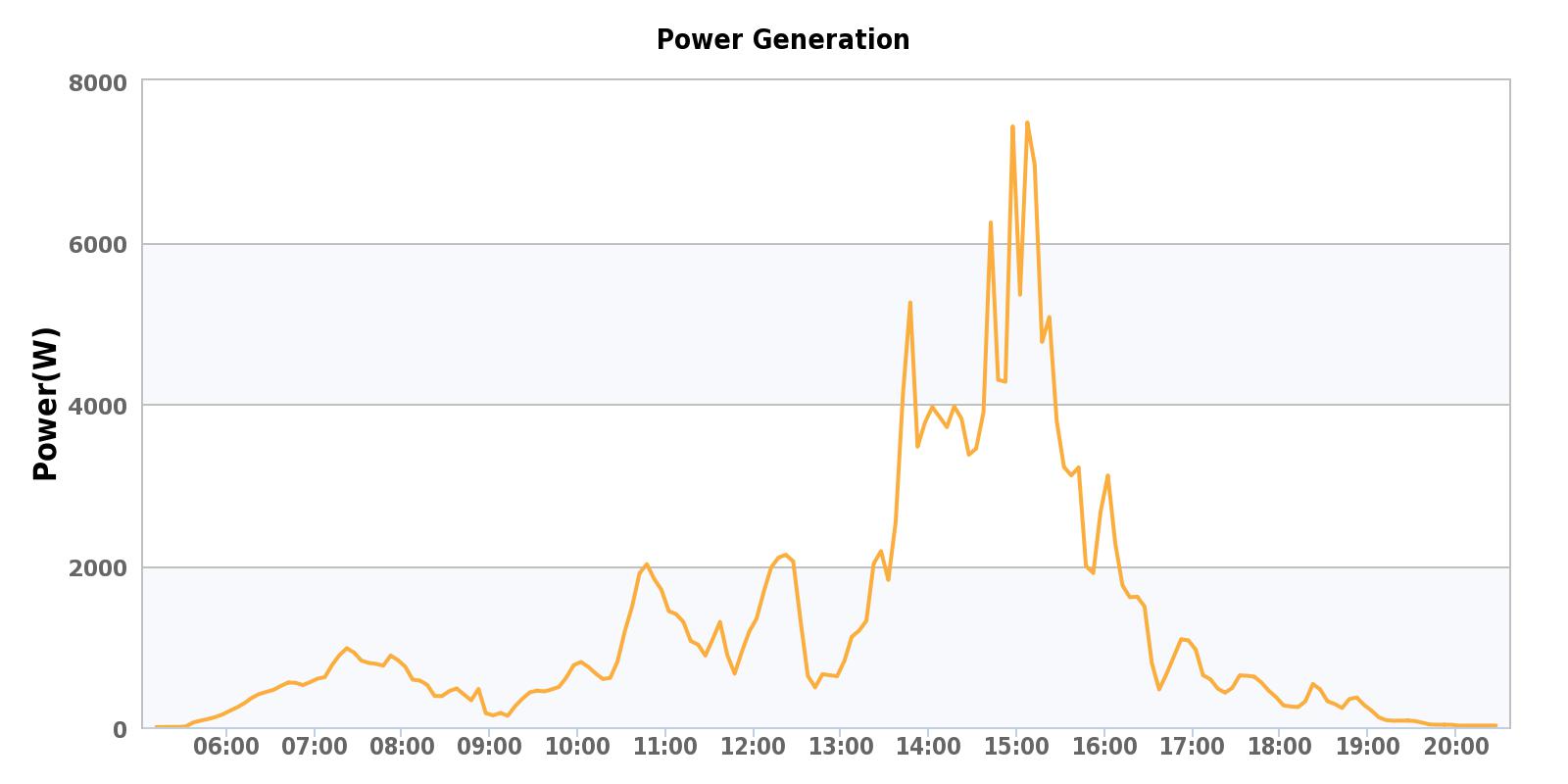
As the clouds and rain change through the day, you can see that the power generated is all over the place. I was impressed that we still achieve over 7000 watts mid-afternoon on that day, if even for a short time.
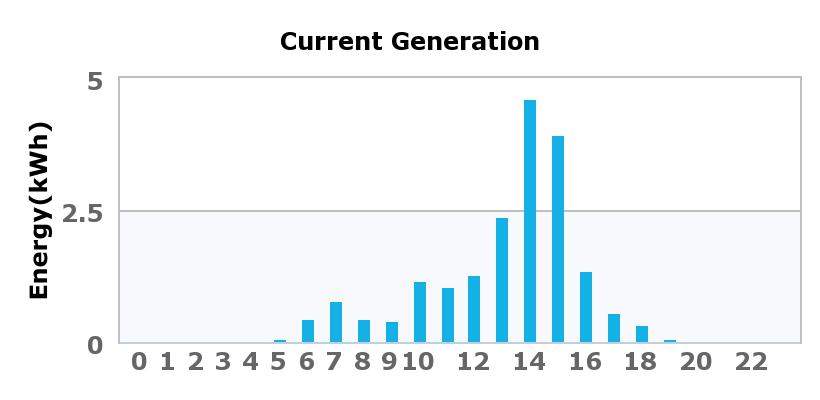 When you consider that there are comparably few days this bad in a given year, and we still generated about 75% of our average daily consumption rate, things are looking pretty good for an overall annual low electric bill.
When you consider that there are comparably few days this bad in a given year, and we still generated about 75% of our average daily consumption rate, things are looking pretty good for an overall annual low electric bill.
All in all pretty promising — and we recently leased a new all-electric BMW i3 which we charge about once every 3 days. That charging activity is included in all the above numbers so we are essentially powering the i3 entirely from the sun. On the flip side, our house contains probably 50 x 65w can lights of which only a few have been converted to LED so far. We could certainly reduce our power consumption a bit more if we converted more of our lighting to LED. But there is a cost to that of course and it’s a long-term project. Assuming our annual out-of-pocket electric cost ends up being zero, there’s really no ROI on replacing our bulbs with LED before the existing bulbs fail on their own.
More on this project later.



