<< Back to Part 2 — Part 3 — Go to Part 4 >>
Disclaimer: Performance Analysis is an art, not a science. Every array is different, every application is different, and every environment has a different mix of both. These posts are an attempt to get you started in looking at what the array is doing and pointing you in a direction to go about addressing a problem. Keep in mind, a healthy array for one customer could be a poorly performing array for a different customer. It all comes down to application requirements and workload. Large block IO tends to have higher response times vs. small block IO for example. Sequential IO also has a smaller benefit from (and sometimes can be hindered by) cache. High IOPS and/or Bandwidth is not a problem, in fact it is proof that your array is doing work for you. But understanding where the high IOPS are coming from and whether a particular portion of the IO is a problem is important. You will not be able to read these series of posts and immediately dive in and resolve a performance problem on your array. But after reading these, I hope you will be more comfortable looking at how the system is performing and when users complain about a performance problem, you will know where to start looking. If you have a major performance issue and need help, open an case.
Starting from the top…
First let’s check the health of the front end processors and cache. The data for this is in the SP Tab which shows both of the SPs. The first thing I like to look at is the “SP Cache Dirty Pages (%)” but to make this data more meaningful we need to know what the write cache watermarks are set to. You can find this by right-clicking on the array object in the upper-left pane and choosing properties. The watermarks are shown in the SP Cache tab.

Once you note the watermarks, close the properties window and check the boxes for SPA and SPB. In the lower pane, deselect utilization and chose SP Cache Dirty Pages (%).
Dirty pages are pages in write cache that have received new data from hosts, but have not been flushed to disk. Generally speaking you want to have a high percentage of dirty pages because it increases the chance of a read coming from cache or additional writes to the same block of data being absorbed by the cache. Any time an IO is served from cache, the performance is better than if the data had to be retrieved from disk. This is why the default watermarks are usually around 60/80% or 70/90%.

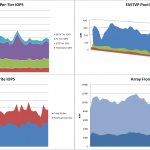
What you don’t want is for dirty pages to reach 100%. If the write cache is healthy, you will see the dirty pages value fluctuating between the high and low watermarks (as SPB is doing in the graph). Periodic spikes or drops outside the watermarks are fine, but repeatedly hitting 100% indicates that the write cache is being stressed (SPA is having this issue on this system). The storage system compensates for a full cache by briefly delaying host IO and going into a forced flushing state. Forced Flushes are high priority operations to get data moved out of cache and onto the back end disks to free up write cache for more writes. This WILL cause performance degradation. Sustained Large Block Write IO is a common culprit here.
While we’re here, deselect Dirty Pages (%) and select Utilization (%) and look for two things here:
1.) Is either SP running at a load of higher than 70%? This will increase application response time. Check whether the SPs seem to fluctuate with the business day. For non-disruptive upgrades, both SPs need to be under 50% utilization.
2.) Are the two SPs balanced? If one is much busier than the other that may be something to investigate.
Now look at Response time (ms) and make sure that, again, both SPs are relatively even, and that Response time is within reasonable levels. If you see that one SP has high utilization and response time but the other SP does not, there may be a LUN or set of LUNs owned by the busy SP that are consuming more array resources. Looking at Total Throughput and Total Bandwidth can help confirm this, and then graphing Read vs. Write Throughput and Bandwidth to see what the IO operations actually are. If both SPs have relatively similar throughput but one SP has much higher bandwidth, then there is likely some large block IO occurring that you may want to track down.
As an example, I’ve now seen two different customers where a Microsoft Sharepoint server running in a virtual machine (on a VMFS datastore) had a stuck process that caused SQL to drive nearly 200MB/sec of disk bandwidth to the backend array. Not enough to cause huge issues, but enough to overdrive the disks in that LUN’s RAID Group, increasing queue length on the disks and SP, which in turn increased SP utilization and response time on the array. This increased response time affected other applications unrelated to Sharepoint.
Next, let’s check the Port Queue Full Count. This is the number of times that a front end port issued a QFULL response back to the hosts. If you are seeing QFULL’s there are two possible causes.. One is that the Queue Depth on the HBA is too large for the LUNs being accessed. Each LUN on the array has a maximum queue depth that is calculated using a formula based on the number of data disks in the RAID Group. For example, a RAID5 4+1 LUN will have a queue depth of 88. Assuming your HBA queue depth is 64 then you won’t have a problem. However, if the LUN is used in a cluster file system (Oracle ASM, VMWare VMFS, etc) where multiple hosts are accessing the LUN simultaneously, you could run into problems here. Reducing the HBA Queue Depth on the hosts will alleviate this issue.
The second cause is when there are many hosts accessing the same front end ports and the HBA Execution Throttle is too large on those hosts. A Clariion/VNX front end port has a queue depth of 1600 which is the maximum number of simultaneous IO’s that port can process. If there are 1600 IOs in queue and another IO is issued, the port responds with QFULL. The host HBA responds by lowering its own Queue Depth (per LUN) to 1 and then gradually increasing the queue depth over time back to normal. An example situation might be 10 hosts, all driving lots of IO, with HBA Execution Throttle set to 255. It’s possible that those ten hosts can send a total of 2550 IOs simultaneously. If they are all driving that IO to the same front end port, that will flood the port queue. Reducing the HBA Execution throttle on the hosts will alleviate this issue.
Looking at the Port Throughput, you can see here that 2 ports are driving the majority of the workload. This isn’t necessarily a problem by itself, but PowerPath could help spread the load across the ports which could potentially improve performance.
In VMWare environments specifically, it is very common to see many hosts all accessing many LUNs over only 1 or 2 paths even though there may be 4 or 8 paths available. This is due to the default path selection (lowest port) on boot. This could increase the chances of a QFULL problem as mentioned above or possibly exceeding the available bandwidth of the ports. You can manually change the paths on each LUN on each host in a VMWare cluster to balance the load, or use Round-Robin load balancing. PowerPath/VE automatically load balances the IO across all active paths with zero management overhead.
Another thing to look for is an imbalance of IO or Bandwidth on the processors. Look specifically at Write Throughput and Write Bandwidth first as writes have the most impact on the storage system and more specifically the write cache. As you can see in this graph, SPA is processing a fair bit more write IOPS compared to SPB. This correlates with the high Dirty Pages and Response Time on SPA in the previous graphs.
So we’ve identified that there is performance degradation on SPA and that it is probably related to Write IO. The next step is to dig down and find out if there are specific LUNs causing the high write load and see if those could be causing the high response times.
<< Back to Part 2 — Part 3 — Go to Part 4 >>