I’ve been having some fun discussions with one of my customers recently about how to tackle various application problems within the storage environment and it got me thinking about the value of having “options”. This customer has an EMC Celerra Unified Storage Array that has Fiber Channel, iSCSI, NFS, and CIFS protocols enabled. This single storage system supports VMWare, SQL, Web, Business Intelligence, and many custom applications.
The discussion was specifically centered on ensuring adequate storage performance for several different applications, each with a different type of workload…
1.) Web Servers – Primarily VMs with general-purpose IO loads and low write ratios.
2.) SQL Servers – Physical and Virtual machines with 30-40% write ratios and low latency requirements.
3.) Custom Application – A custom application database with 100% random read profiles running across 50 servers.
The EMC Unified solution:
EMC Storage already sports virtual provisioning in order to provision LUNs from large pools of disk to improve overall performance and reduce complexity. In addition, QoS features in the array can be used to provide guaranteed levels of performance for specific datasets by specifying minimum and maximum bandwidth, response time, and IO requirements on a per-LUN basis. This can help alleviate disk contention when many LUNs share the same disks, as in a virtual pool. Enterprise Flash Drives (EFD) are also available for EMC Storage arrays to provide extremely high performance to applications that require it and they can coexist with FC and SATA drives in the same array. Read and write cache can also be tuned at an array and LUN level to help with specific workloads. With the updates to the EMC Unified Platform that I discussed previously, Sub-LUN FAST (auto tiering), and FAST Cache (EFD used as array cache) will be available to existing customers after a simple, non-disruptive, microcode upgrade, providing two new ways to tackle these issues.
So which feature should my customer use to address their 3 different applications?
Sub-LUN FAST (Fully Automated Storage Tiering)
Put all of the data into large Virtual Provisioning pools on the array, add a few EFD (SSD) and SATA disks to the mix and enable FAST to automatically move the blocks to the appropriate tier of storage. Over time the workload would even out across the various tiers and performance would increase for all of the workloads with much fewer drives, saving on power, floor space, cooling, and potentially disk cost depending on the configuration. This happens non-disruptively in the background. Seems like a no-brainer right?
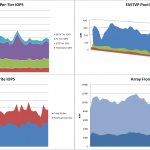
For this customer, FAST helps the web server VMs and the general-purpose SQL databases where the workload is predominately read and much of the same data is being accessed repeatedly (high locality of reference). As long as the blocks being accessed most often are generally the same, day-to-day, automated tiering (FAST) is a great solution. But what if the workload is much more random? FAST would want to push all of the data into EFD, which generally wouldn’t be possible due to capacity requirements. Okay, so tiering won’t solve all of their problems. What about FAST Cache?
FAST Cache
Exponentially increase the size of the storage array’s read AND write cache with EFD (SSD) disks. This would improve performance across the entire array for all “cache friendly” applications.
For this customer, increasing the size of write cache definitely helps performance for SQL (50% increase in TPM, 50% better response time as an example) but what about their custom database that is 100% random read? Increasing the size of read cache will help get more data into cache and reduce the need to go to disk for reads, but the more random the data, the less useful cache is. Okay, so very large caches won’t solve all of their problems. EFDs must be the answer right?
EFD Disks
Forget SATA and FC disks; just use EFD for everything and it will be super fast!! EFD has extremely high random read/write performance, low latency at high loads, and very high bandwidth. You will even save money on power and cooling.
The total amount of data this customer is dealing with in these three applications alone exceeds 20TB. To store that much in EFD would be cost prohibitive to say the least. So, while EFD can solve all of this customer’s technical problems, they couldn’t afford to acquire enough EFD for the capacity requirements.
But wait, it’s not OR, it’s AND
The beauty of the EMC Unified solution is that you can use all of these technologies, together, on the same array, simultaneously.
In this customer’s case, we put FC and SATA into a virtual pool with FAST enabled and provision the web and general-purpose SQL servers from it. FAST will eventually migrate the least used blocks to SATA, freeing the FC disks for the more demanding blocks.
Next, we extend the array cache using a couple EFDs and FAST Cache to help with random read, sequential pre-fetching, and bursty writes across the whole array.
Finally, for the custom 100% random read database, we dedicate a few EFDs to just that application, snapshot the DB and present copies to each server. We disable read and write cache for the EFD backed volumes which leaves more cache available to the rest of the applications on the array, further improving total system performance.
Now, if and when the customer starts to see disk contention in the virtual pool that might affect performance of the general-purpose SQL databases, QoS can be tuned to ensure low response times on just the SQL volumes ensuring consistent performance. If the disks become saturated to the point where QoS cannot maintain the response time or the other LUNs are suffering from load generated by SQL, any of the volumes can be migrated (non-disruptively) to a different virtual pool in the array to reduce disk contention.
Options
If you look at offerings from the various storage vendors, many promote large virtual pools, some also promote large caches of some kind, others promote block level tiering, and a few promote EFD (aka SSDs) to solve performance problems. But, when you are consolidating multiple workloads into a single platform, you will discover that there are weaknesses in every one of those features and you are going to wish you had the option to use most or all of those features together.
You have that option on EMC Unified.